
szhshp
"Proud to Be Different"
- Home
- Archives
- Posts181
- Comics20
- Tags181
- Life
- Music
- Game
- Reading
- Footprint
- Photos
- Language
- zh-CN
- en-US
- RSS
- Search
- Friends
- History
- About
首先我有一个 Item 的 collection:
type Item {
_id: String
itemname: String!
itemid: String!
itemtype: String!
parent_id: String
}
///////////////////
/// 主要是下面这一些部分
type Query {
getItemSummary: ItemSummaryResponse
}
type ItemSummaryResponse {
data: [ItemSummary]
success: Boolean
}
type ItemSummary {
_id: String
count: Int
}
gql 端调用的方法:
{
getItemSummary {
data{
_id
count
}
success
}
}
然按照其中的类别 (itemtype) 进行总计:
那么实际上在后台 mongoose 里面需要这么写:
getItemSummary: root => Item.aggregate([{
$group: {
_id: '$itemtype',
count: {
$sum: 1,
},
},
}, ]).then((res) => {
if (res === null) {
return {
success: 0,
errors: ['sadfsdfsdf']
};
}
return ({
success: 1,
errors: [],
data: res,
});
}),
首先写明按照哪个 field 进行聚合
$group: {
_id: '$itemtype',
// 这个地方比较重要,首先左边一定要写成 _id, 最后在前端通过 gql 取的时候也是写 _id
// 另外重要是这个 key 的值是 $itemtype, 说明根据 itemtype 进行 group, 直接写 $ + fieldname 即可
count: {
$sum: 1,
},
},
因为 $group 里面对应需要聚合操作的列必须写成 _id , 否则会出现 The field 'xxx' must be an accumulator object 的报错信息
另外 SQL 的聚合函数都可以用到这里:
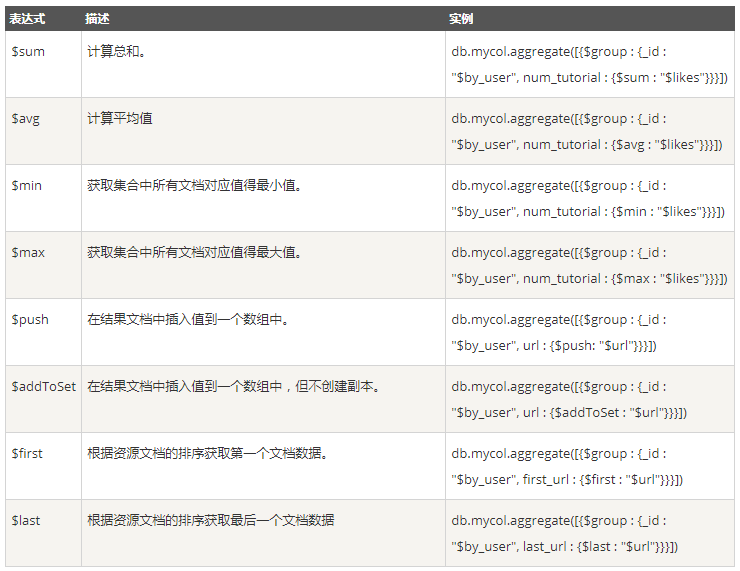
管道在 Unix 和 Linux 中一般用于将当前命令的输出结果作为下一个命令的参数。
基本上就是逐个执行聚合方法里面的方法.
上方的聚合函数仅仅执行了对一个 field 的聚合:
Item.aggregate([{
$group: {
_id: '$itemtype',
count: {
$sum: 1
}
}
}, ])
但是实际上可以在这些操作之前之后加更多的操作.
比如想要将,70 分到 90 分之间的数据先筛选出来再进行 group:
db.articles.aggregate([{
$match: {
score: {
$gt: 70,
$lte: 90
}
}
},
{
$group: {
_id: null,
count: {
$sum: 1
}
}
}
]);
$project 实例
0 为不显示,1 为显示,默认情况下 _id 字段是 1
db.articles.aggregate({
$project: {
_id: 0,
title: 1,
by_user: 1,
}
});
// 返回
{ "title" : "MongoDB Overview", "by_user" : "runoob.com" }
{ "title" : "NoSQL Overview", "by_user" : "runoob.com" }
{ "title" : "Neo4j Overview", "by_user" : "Neo4j" }
$match 实例
$match 用于获取分数大于 70 小于或等于 90 记录,然后将符合条件的记录送到下一阶段$group 管道操作符进行处理。
db.articles.aggregate([{
$match: {
score: {
$gt: 70,
$lte: 90
}
}
},
{
$group: {
_id: null,
count: {
$sum: 1
}
}
}
]);
// 返回
{ "_id" : null, "count" : 1 }
$skip 实例
经过 $skip 管道操作符处理后,前 2 个文档被"过滤"掉。
db.col_1.aggregate({ $skip: 2 });
| 文章标题 | Mongoose: aggregate() 方法实现聚合函数 |
| 发布日期 | 2019-09-07 |
| 文章分类 | Tech |
| 相关标签 | #MongoDB #Mongoose #GraphQL |